Cómo usar expresiones regulares en chatbots
Las expresiones regulares son patrones que se pueden utilizar cuando los métodos de validación preestablecidos son insuficientes para comparar un valor recibido de un suscriptor con un valor de plantilla.
Por ejemplo, puede utilizar expresiones regulares para comprobar una frase en busca de palabras clave y recuento de palabras, la presencia de espacios y otros caracteres, así como para introducir números dentro de un intervalo de valores determinado o comprobar si hay un vínculo a una cuenta de redes sociales.
Caracteres Regulares Syntax
Puede componer una expresión regular a partir de caracteres regulares, como /abc/, o combinar caracteres regulares y especiales, como /ab*c/.
En las tablas siguientes, puede ver los símbolos básicos que se utilizan al componer una expresión regular.
Símbolos especiales
\ |
Carácter de blindaje. Indica que el siguiente carácter es un carácter literal y no un metacarácter. Por ejemplo, \* corresponde a un asterisco como carácter literal, no como cuantificador de repetición |
\n |
Nueva Linea. Se utiliza para buscar fuentes de línea. Por ejemplo, /\n corresponde a un salto de línea.
"Trabaja duro. Sueña en grande." |
\t |
Tab. Se utiliza para buscar el carácter de tabulación horizontal en cadenas (caractér ASCII 9). |
\v |
Pestaña vertical. Corresponde a cualquier carácter de espacio vertical. |
\f |
Nueva página. Corresponde a ASCII caractér 12. |
Anclas
^ |
El comienzo de la línea. Por ejemplo, /^B/ no corresponde a "B" en "a B", pero sí en "B a". |
$ |
Al final de la línea. Por ejemplo, /k$/ no coincide con "k" en "walker", pero coincide con la línea "walk". |
\b |
Límite de palabras. Por ejemplo, /\bpump/ corresponde a "bomba" en "calabaza". |
Clases de símbolos
\s |
Espacio. Por ejemplo, /\s/ corresponde al primer espacio de la línea que suena increíble. Si se utiliza el indicador de búsqueda global g, /\s/g corresponde a dos caracteres en la cadena "eso suena increíble". |
\d |
Cifra. Es igual al primer dígito de la línea. Equivalente a /[0-9]/. Por ejemplo, /\d/ corresponde a "2", pero no corresponde a "B" en la línea "B2 es el número de suite". |
\D |
No es un número. Es igual a la primera letra de la cadena. Equivalente a /[^0-9]/. Por ejemplo, /\D/ corresponde a "B", pero no corresponde a "2" en la línea "B2 es el número de suite". |
\w |
Palabra. Corresponde a cualquier primer carácter alfanumérico, incluido el guión bajo. Equivalente a /[A-Za-z0-9_]/. Por ejemplo, /\w/ corresponde a "b" en "banco" y "3" en "$3.52". |
\W |
No es una palabra. Corresponde a cualquier primer non-digit-letter caracter. Equivalente a la expresión /[^A-Za-z0-9_]/.
Por ejemplo, |
Cuantificadores
* |
0 o mayor. Corresponde al carácter anterior repetido 0 o más veces. Equivalente a la expresión /{0,}/. Por ejemplo, /les*/ corresponde a "less" en "Endless love" y "le" en "let it be." |
+ |
1 o mayor. Corresponde al carácter anterior repetido 1 o más veces. Equivalente a la expresión /{1,}/.
Por ejemplo, |
? |
0 or 1. Corresponde al carácter anterior repetido 0 o 1 veces. Equivalente a la expresión /{0,1}/. Por ejemplo, /colou?r/ corresponde a los dos "color" y "colour," o /mo?ustache/ corresponde a ambos "moustache" y "mustache." |
{n} |
Exactly N times. Por ejemplo, /a{2}/ no corresponde a "a" en la línea "sugar," pero sí corresponde a ambas instancias de "a" in the string "sugaar" y las primeras dos "a" in the string "sugaaar." |
{n, m} |
Veces mínimas N y máximo M. Por ejemplo, /a{1,3}/ corresponde a nada en la línea "sugr," pero corresponde al caracter "a" en la lína "sugar," two instances of "a" in the string "sugaar," and the first three instances of "a" in the string "sugaaaaaaaar." |
Ranges
. |
Cualquier carácter que no sea un salto de línea (/\n/). Por ejemplo, /.e/ corresponde a "ke" en la línea "Take care! Si se utiliza el indicador de búsqueda global g es usado, la expresión /.e/g corresponde a "ke" and "re" en la línea "Take care! |
(a|b) |
a or b. Por ejemplo, /(green|red)/ corresponde a "green" en "green or red apple?" and /(red|green)/ corresponde a "red" en "green or red apple?". |
(...) |
Grupo de caracteres. Por ejemplo, /(...e)/ corresponde a “tener” en la cadena “tener un buen día!” Si se utiliza la bandera de búsqueda global g, la expresión /(...e)/g corresponde a "Have" y "nice"” en la cadena “tener un buen día! |
[abc] |
a, or b, or c. Por ejemplo, /[abcd]/ corresponde al caracter "b" en la línea g "basket". If the global search flag g is used, the expression /[abcd]/g corresponde a los caracteres "b" and "a" in the string "basket." |
[a-q] |
La letra entre a y q en minúsculas. Por ejemplo, /[e-m]/ corresponde al caracter "k" en la línea "basket". If the global search flag g is used, the expression /[e-m]/g corresponds to the characters "k" and "e" in the string "basket." |
[A-Q] |
La letra entre A y Q en mayúscula. Por ejemplo, /[E-M]/ corresponde al caracter "K" en la línea "BASKET". Si se utiliza el indicador de búsqueda global g , la expresión /[E-M]/g corresponde a los caracteres "K" y "E" de la cadena "BASKET". |
[^abc] |
No a, b, o c. Por ejemplo, /[^abcd]/ corresponde al caracter "s" en la línea "basket". Si utiliza el indicador de búsqueda global g, la expresión /[^abcd]/g corresponde a los caracteres "s," "k," "e," y "t" en la línea "basket." |
[^a-q] |
Any lowercase letter that is not in the range a to q. For example, /^[e-m]/ corresponds to the character "b" in the string "basket." If you use the global search flag g, then /^[e-m]/g matches the characters "b", "a", "s" and "t" in the string "basket." |
[0-9] |
A digit between 0 and 9. For example, /[1-5]/ corresponds to the number "2" in the string "B255 is the suite number." If the global search flag g is used, the expression /[1-5]/g corresponds to the digits "2," "5," and "5" in the string "B255 is the suite number." |
Indicadores
Nota que los indicadores se especifican después de la expresión regular. El orden de las banderas no importa.
g |
Búsqueda global. Por ejemplo, /m/g corresponde a ambas instancias de "m" en la cadena "moments". Sin la g, el patrón /m/ corresponde a la primera "m" en la cadena "moments". |
i |
Una búsqueda de region-independiente. Por ejemplo, /m/i corresponde a "M" en la línea "Moments”. Sin la i, el /m/i no corresponde a "M" al caracter en la línea "Moments". |
m |
Multi-line text. Por ejemplo, /^\D/gm corresponde a los caracteres "W" y "D" en las siguientes líneas.
"Work hard. Dream big." |
s |
Lee el texto como una sola línea. El texto se trata como una sola línea, en cuyo caso el metacarácter “.” corresponde a cualquier carácter individual, incluido el carácter de nueva línea. |
Meta-caracteres
Los meta-caracteres son caracteres que no son letras o números, pero tienen un papel específico en la sintaxis de una expresión regular. Por ejemplo, * Es un cuantificador de repetición.
Para utilizar un meta-carácter para un propósito diferente, necesita ser escapado. Por ejemplo, para que el símbolo * ya no sea un cuantificador de repetición, sino un símbolo de asterisco.
El blindaje se realiza con el carácter \ barra invertida. Por ejemplo, \. , \/, \* y así sucesivamente.
Consulta la tabla a continuación para ver los personajes que deben escaparse.
| ^ | [ | . | $ | { | * | ( |
| \ | + | ) | | | ? | < | > |
Para aprender más sobre expresiones syntax regulares, ve la tabla exlab.net.
Cómo usar expresiones regulares en SendPulse Chatbot Builder
Arrastra y suelta el elemento Mensaje desde el panel izquierdo del creador de chatbots. Activa la opción "Esperar la respuesta del suscriptor". Selecciona la validación "Expresión regular".
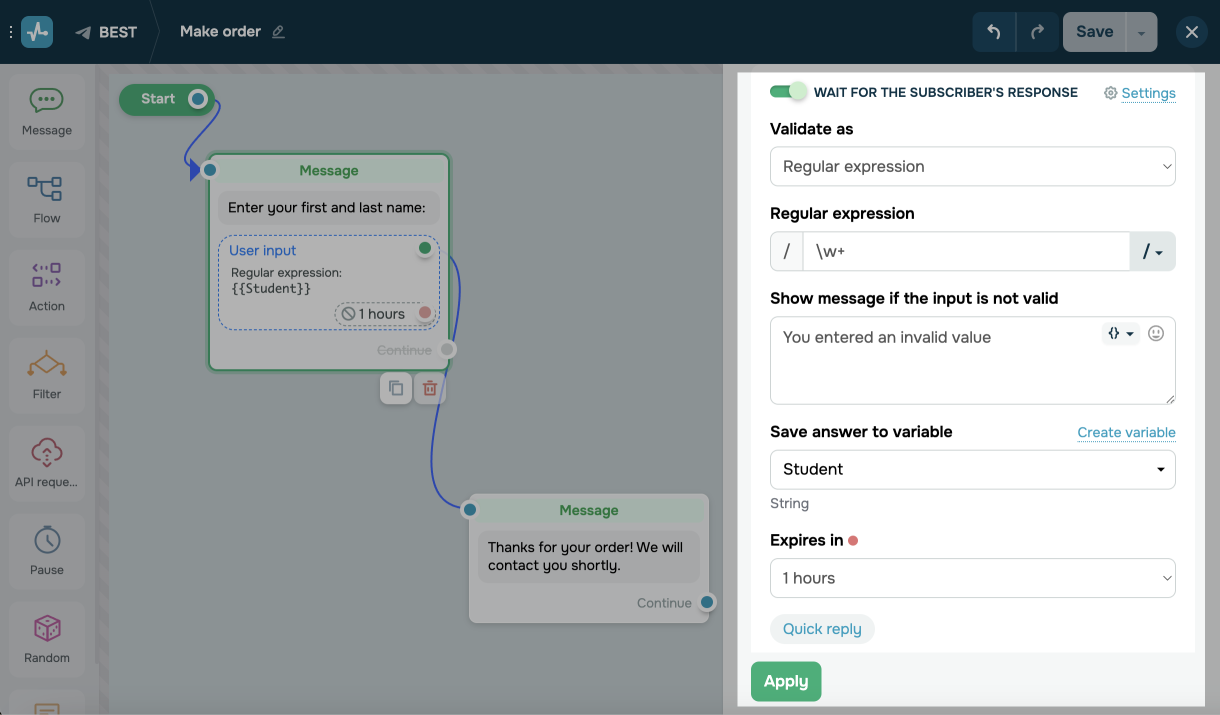
Introduce tu expresión en el campo Expresión regular. Veremos un ejemplo de una expresión para comprobar si ingresó "Sí" y "No" con diferentes casos.
Puedes comprobar la validez de la expresión regular en el sitio web regex101. Allí, en la sección "Biblioteca Regex", puedes encontrar plantillas de expresiones de uso común con explicaciones.
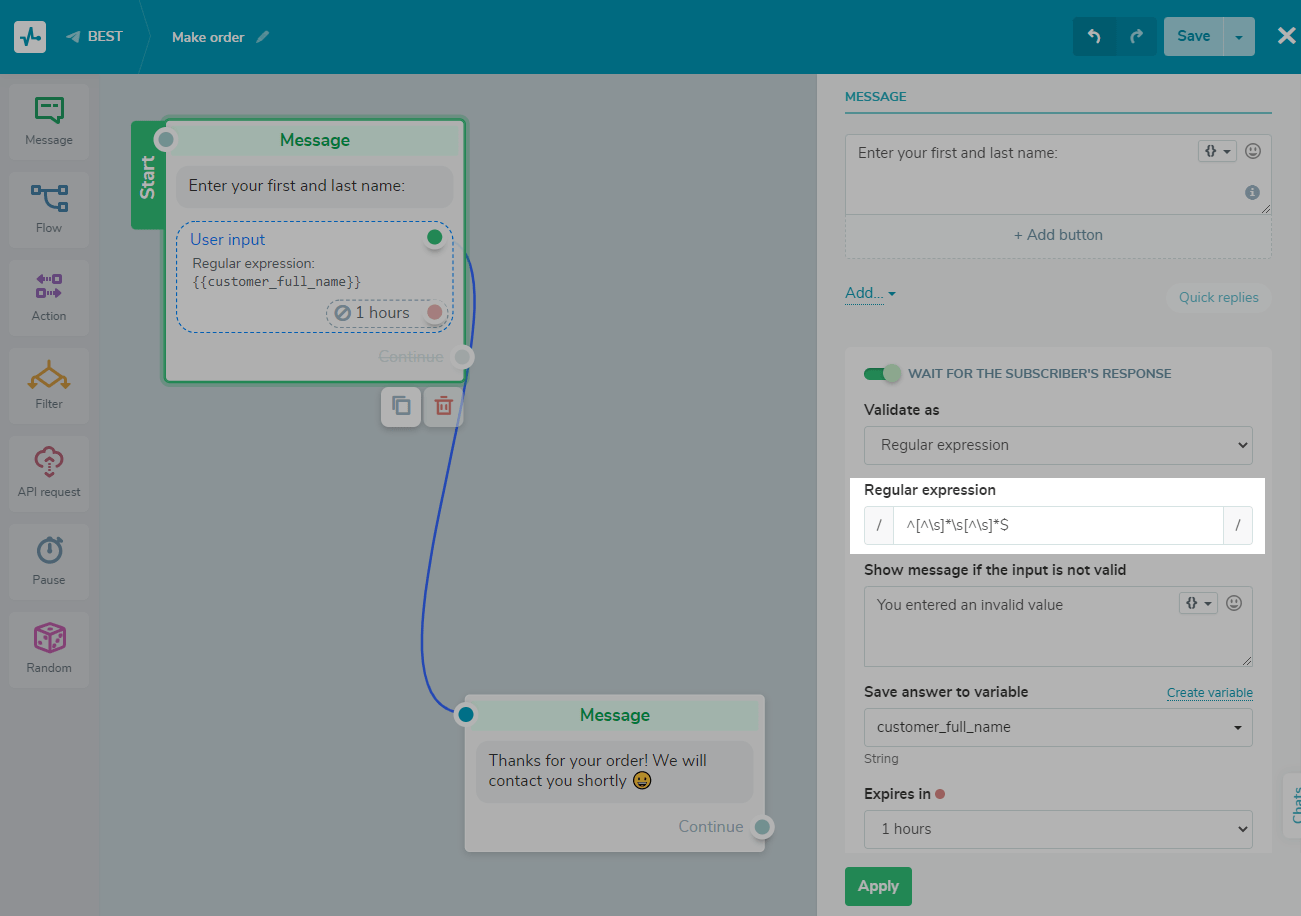
Introduce el mensaje que aparecerá cuando se introduzcan datos de forma incorrecta. Puedes utilizar variables y emojis.
Te recomendamos que cambies el mensaje de error predeterminado y especifiques lo que deseas obtener en respuesta con un valor de ejemplo para facilitar al usuario la navegación por el bot y proporcionar los datos correctos.
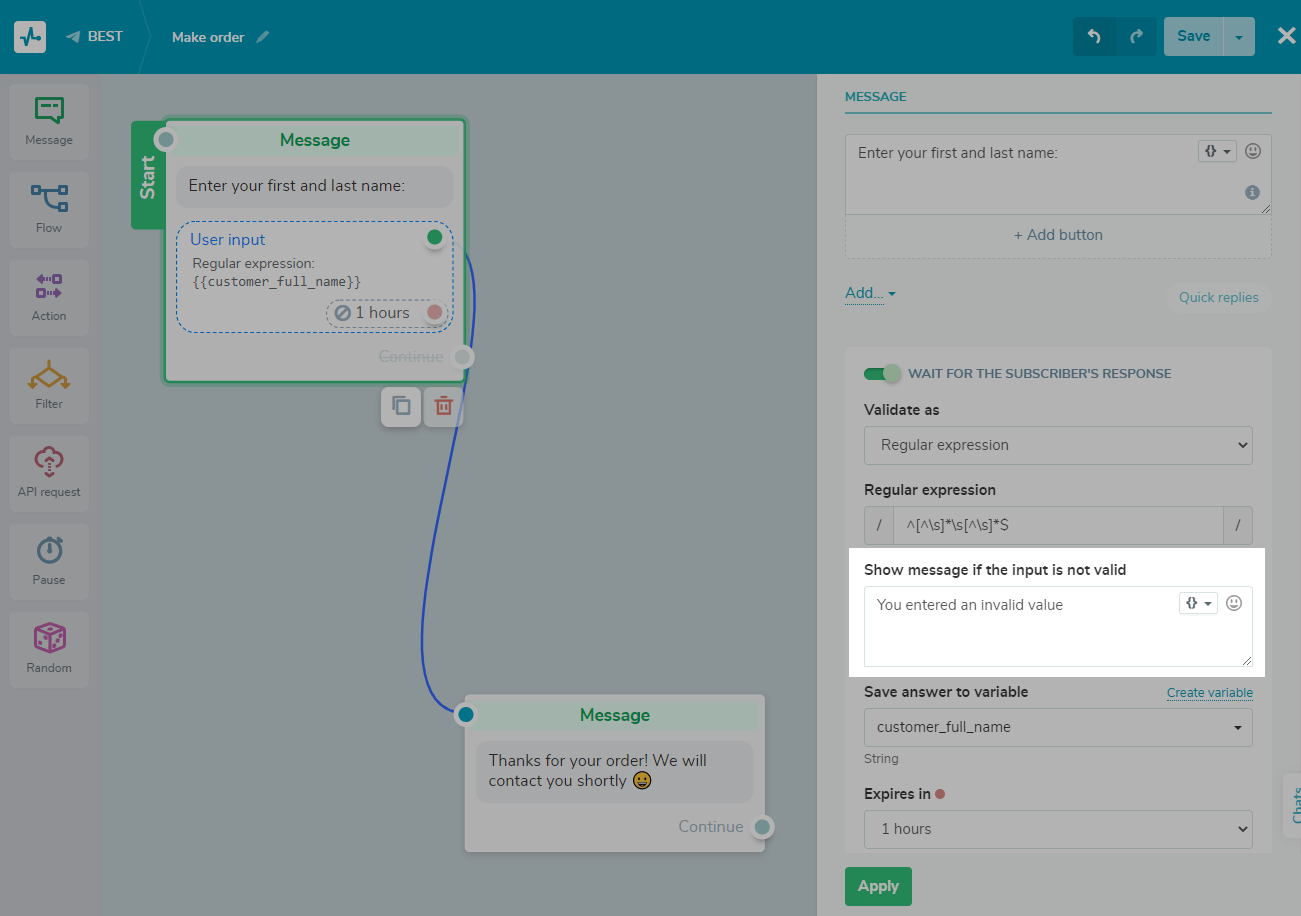
Selecciona la variable en la que deseas guardar la respuesta o crea una nueva haciendo clic en "Crear variable".
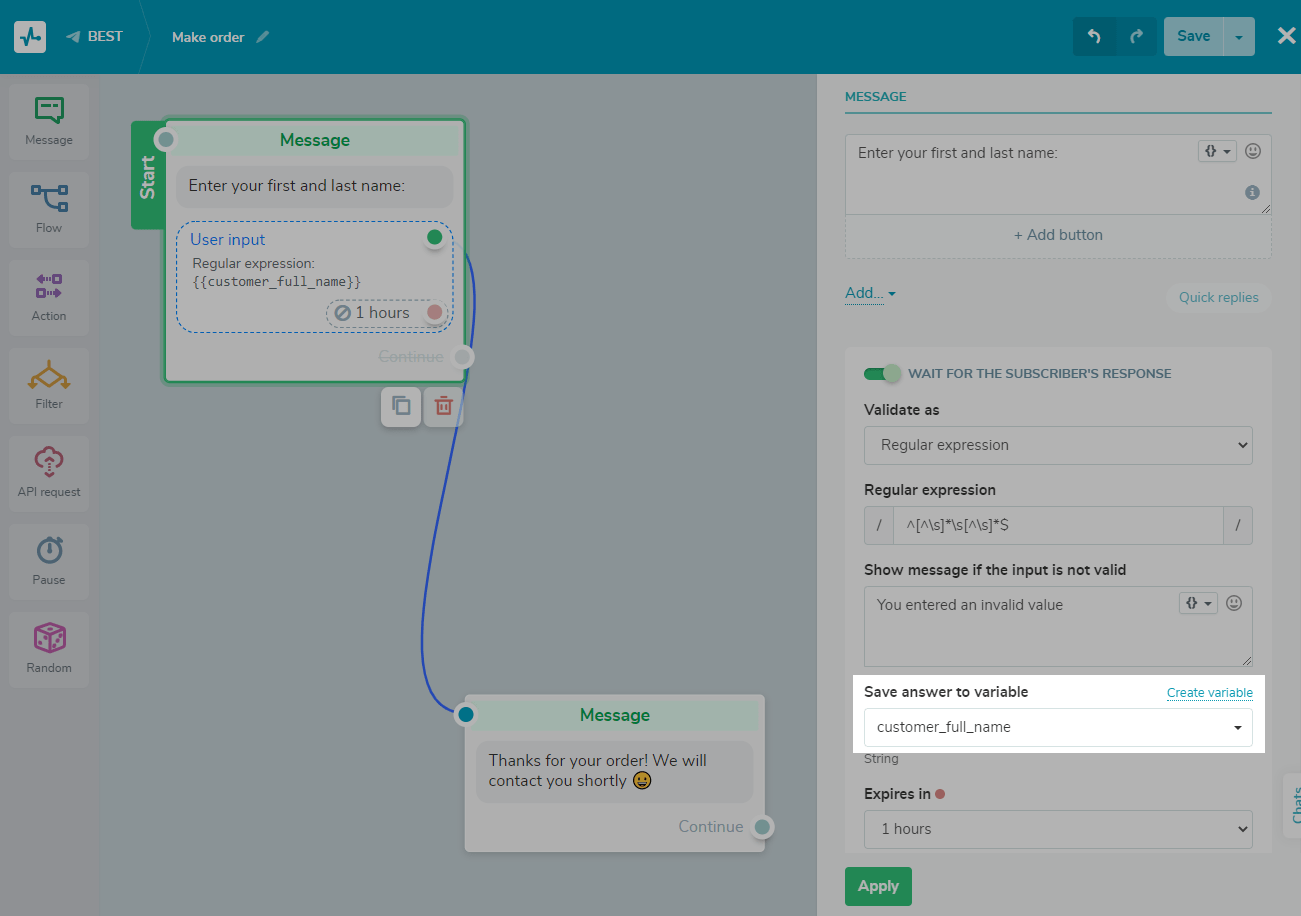
No olvides establecer un período de espera para la respuesta para evitar que el usuario ingrese valores que no sean los que ha solicitado durante un período de tiempo.
Nota: cuando el elemento "Entrada de usuario" está esperando una respuesta, la activación de otros flujos por desencadenadores y clics en el menú no funciona.
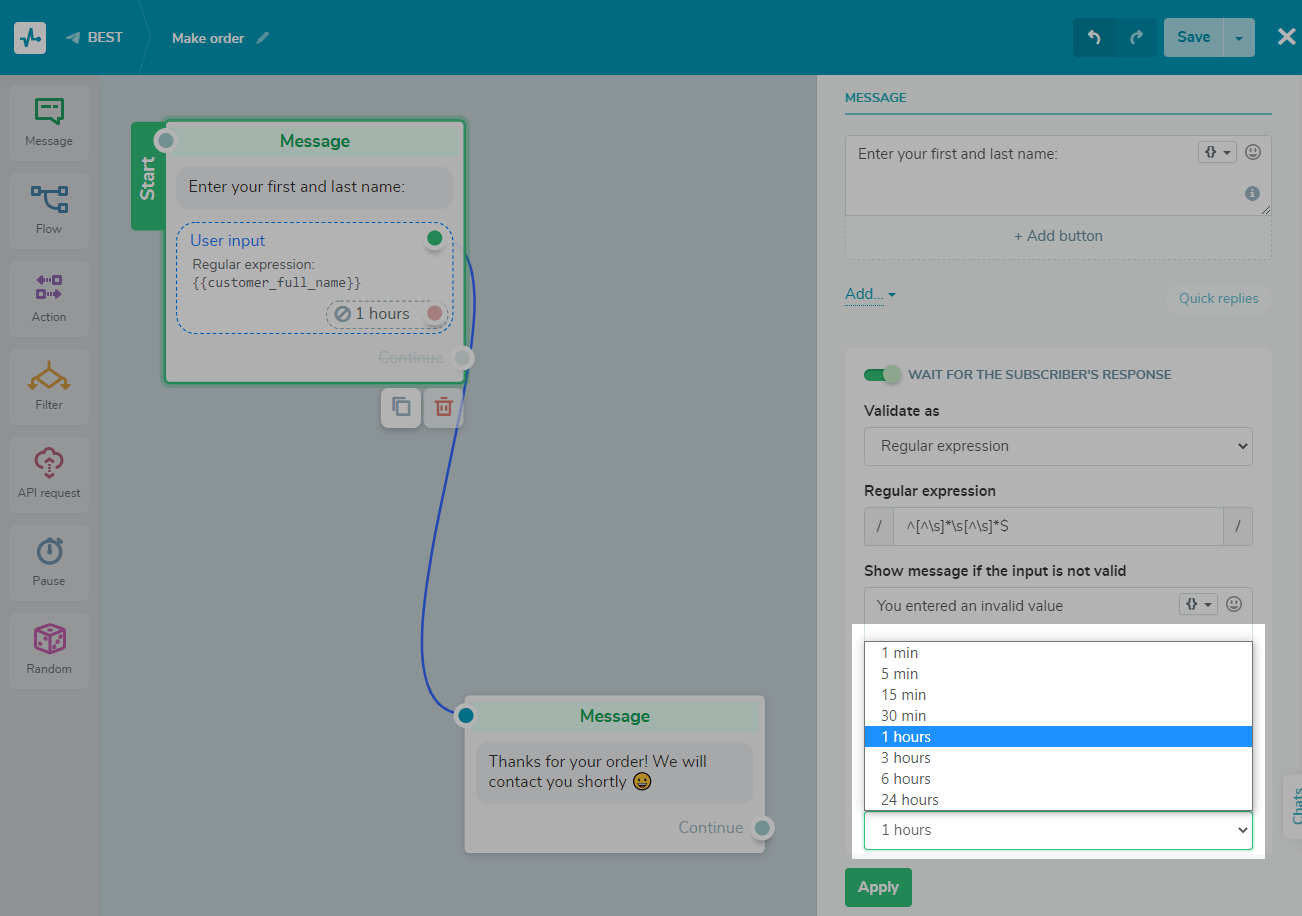
Da click en "Aplicar.”
Cómo interactúan los usuarios con el bot mediante una expresión regular
Ejemplo de uso de expresiones regulares para comprobar cuantitativamente la introducción de una frase de dos palabra /^[^\s]*\s[^\s]*$/.
Si un suscriptor introduce un número incorrecto de palabras, recibirá un mensaje de entrada incorrecto. Si el número de palabras es correcto, el suscriptor recibirá un mensaje de éxito.
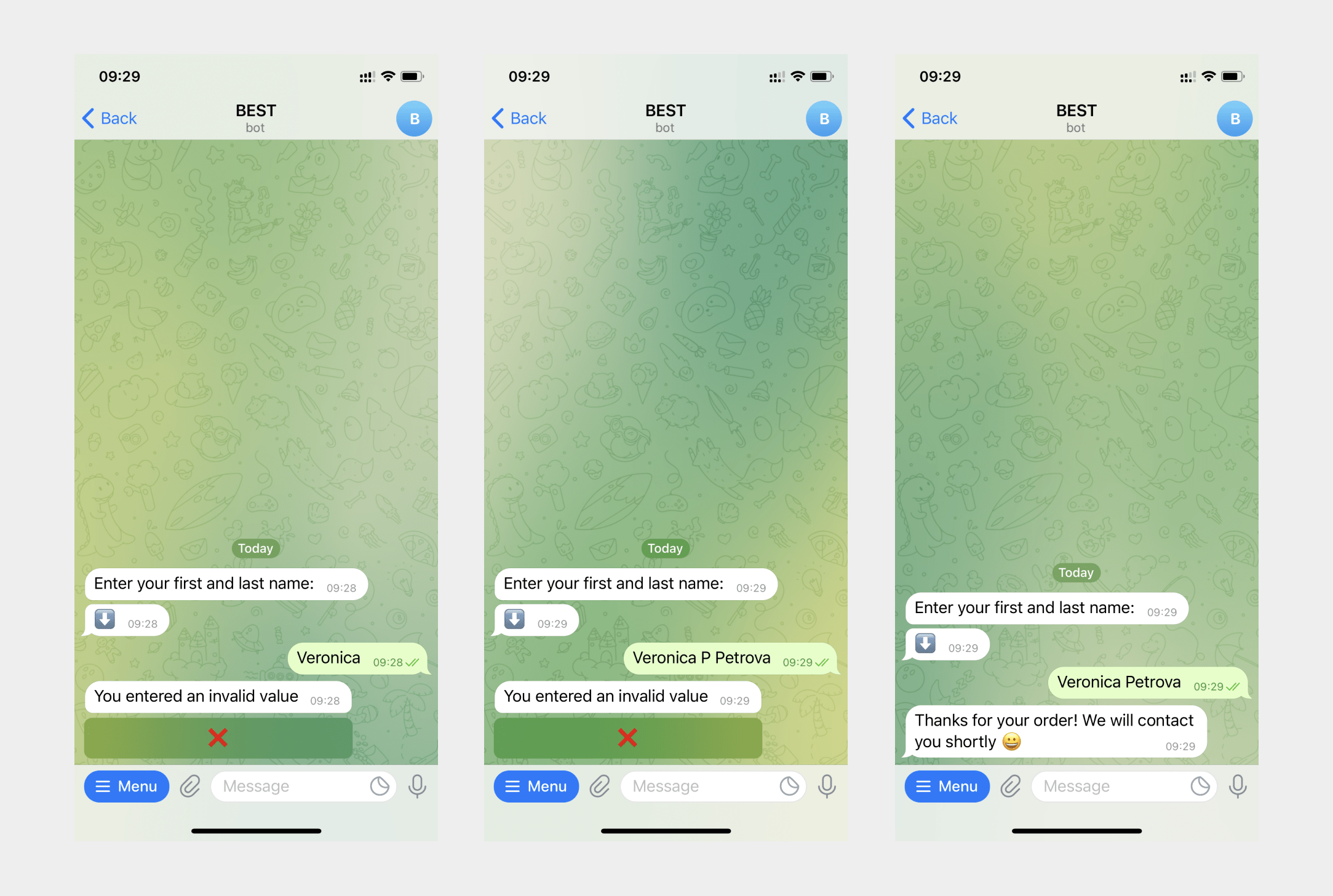
Un ejemplo de uso de expresiones regulares para preguntas dicotómicas con declaraciones "Sí" y "No".
En el "Mensaje" agregamos una pregunta y dos botones, e introduzca datos de usuario con una expresión regular ^(?:Yes|No|)$, donde ?: ingresamos los valores que queremos obtener y escribimos en una variable, | - operator "or,” ^ y $ denota el principio y el final de la cadena. Si el usuario no hace clic en uno de los botones pero introduce su propio texto, que no es relevante para la respuesta esperada, el mensaje le recordará que introduzca o haga clic en una de las sentencias si los datos se introducen incorrectamente.
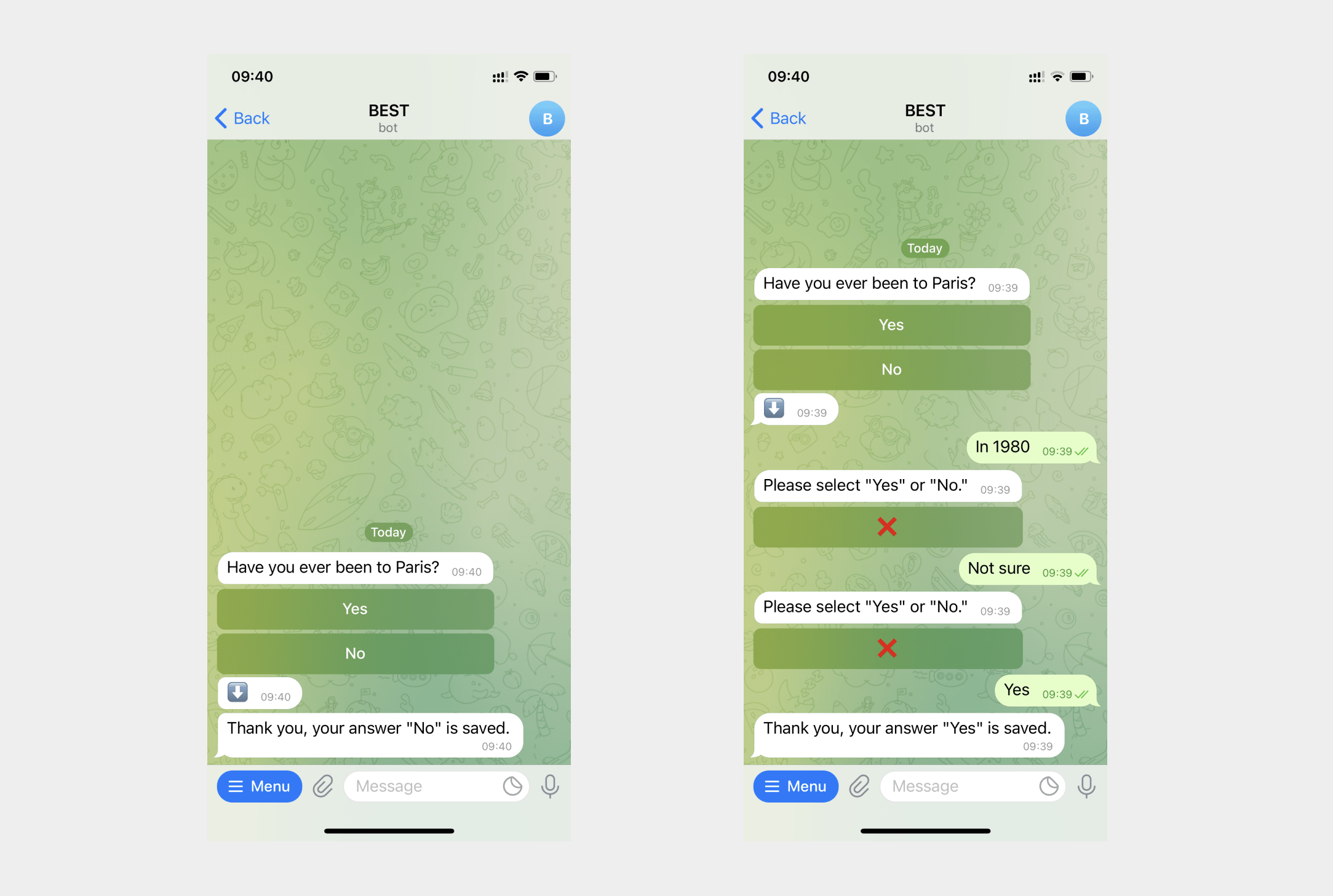
Un ejemplo de uso de expresiones regulares para consultar una dirección de correo electrónico en gmail.com.
En el bloque "Mensaje", agrega una pregunta y una entrada de usuario con la expresión regular (\w|^)[\w.\-]{0.25}@(gmail)\.com(\w|$). Ve este mensaje descodificado a continuación.
Si un usuario introduce un correo electrónico en un dominio distinto de gmail.com,", el mensaje le recordará que introduzca un correo electrónico en el dominio gmail.com para acceder a Google Docs, si los datos no se introducen correctamente.
Ten en cuenta que los datos escritos mediante expresiones regulares se escriben en variables del tipo String. No podrás enviarles campañas en el servicio. Para recopilar datos de contacto para enviar mensajes, utiliza los tipos de entrada de datos Correo electrónico y Teléfono.
Las respuestas con datos de los usuarios se guardan en variables de audiencia de chatbot. Puedes ver las respuestas guardadas en la ficha Audiencia, utilizar las variables en todos los mensajes de texto posteriores y crear correos con segmentación.
Ejemplos de expresiones regulares
Checar una fecha en formato DD/MM/YYYY:
/\d{1,2}\/\d{1,2}\/\d{4}/
- Explicación:
\d- esperar a que se introduzcan los dígitos;{1,2}- Puede haber uno o dos dígitos totales ({1,2};\.- proteger el "." para que aparezca como un punto normal.
Verificar una fecha en formato DD.MM.YYYY:
/\d{1,2}\.\d{1,2}\.\d{4}/
- Explicación:
\d- esperar a que se introduzca cualquier dígito;{1,2}- Puede haber uno o dos dígitos totales ({1,2};\.- proteger el "." para que aparezca como un punto normal;{4}- deben haber cuatro dígitos totales{4}.
Para comprobar si hay una palabra por línea:
/^[^\s]*$/
- Explicación:
^- inicio de la línea;[^\s]- cualquier carácter, sin un espacio después de cada carácter;*- 0 o más veces;$- final de la línea.
Para comprobar si hay dos palabras en una línea:
/^[^\s]*\s[^\s]*$/- Explicación:
^- inicio de la línea;[^\s]- cualquier carácter, sin ningún espacio después de cada carácter;*- 0 o más veces;\s- espacio;[^\s]- cualquier carácter, sin un espacio después de cada carácter;*- 0 o más veces;$- final de la línea.
Para checar si hay tres palabras en una línea:
/^([^\s]*\s){2}[^\s]*$/
- Explicación:
^- inicio de la línea;([^\s]*\s){2})hay dos palabras ({2}), cada uno formado por cualquier carácter, sin algún espacio; después de cada carácter ([^\s]), el cual puede ser 0 o más veces (*); cada palabra termina con un espacio (\s);[^\s]- cualquier carácter, sin ningún espacio después del carácter;*- 0 o más veces;$- final de la línea.
Para comprobar si hay una coincidencia de palabras específicas:(e.g. Yes, yes, YES, or No, no, NO):
/^(?:Yes|Yes|YES|No|no|NO)$- Explicación:
^- inicio de la línea;?:- pendiente de la entrada de palabras que coincidan con las introducidas;Yes|Yes|Yes|No|Noson las palabras yes, Yes, YES, no, No, NO para revisar que coincidan;$- final de la línea.
Expresión regular para comprobar la serie y el número del pasaporte (como dos letras y seis dígitos sin espacio para el modelo antiguo o xxxxxxxx-xxxxxxx para el nuevo modelo):
/^([A-Z]{2}[0-9]{6})?$|[0-9]{8}[\s\-]?[0-9]{5}?$/- Explicación:
^- inicio de la línea;([A-Z]{2}[0-9]{6})?- una línea puede ser repetida 0 or 1 veces (?), el cual consiste en dos caracteres ({2}) entre A y Z ([A-Z]) seguido de seis ({6}) dígitos de cualquier valor ([0-9]);$- final de la línea;|- o;[0-9]{8}- ocho ({8}) dígitos de cualquier valor ([0-9]);[\s\-]?- espacio y guión ([\s\-]), el cual puede ser repetido 0 o 1 vez;[0-9]{5}- cinco ({5}) cualquier dígito ([0-9]);[\s\-]?- un conjunto de 8 dígitos, un guión y 5 dígitos que se pueden repetir 0 o 1 vez;$- final de la línea.
Para checar TIN (of 10 or 12 digits):
/^(([0-9]{12})|([0-9]{10}))?$/- Explicación:
^- inicio de la línea;[0-9]{12}- doce ({12}) dígitos entre 1 y 9 ([0-9]);|- operador "o";[0-9]{10}- diez ({10}) dígitos ([0-9]);?- el cual puede ser repetido 0 o 1 vez;$- final de la línea.
Para verificar un número de cuenta de banco en el formato xxxx-xxxxxx-xxxx-xxxx:
/\d{4}[\s\-]?\d{4}[\s\-]?\d{4}[\s\-]?\d{4}/- Explicación:
\d- esperando a que se introduzcan los dígitos;{4}- de los cuales solo puede haber cuatro;[\s\-]?- espacio y guión, que se pueden repetir 0 o 1 vez.
Para verificar las direcciones de correo electrónico de los dominios (por ejemplo, para compartir documentos de una cuenta de Google con una dirección de gmail.com):
/(\w|^)[\w.\-]{0,25}@(gmail)\.com(\w|$)/- Explicación:
(\w|^)- la primera parte de la captura, donde\w- corresponde a cualquier carácter de texto,^indica la posición al principio de la línea;[\w.\-]- corresponde a uno de los caracteres de la lista, donde\w- corresponde a cualquier carácter del texto,.corresponde al carácter "." y . corresponde "-";{0,25}- de los cuales puede haber en cualquiera de 0 to 25;(gmail)- corresponde a la palabra "gmail";\.- corresponde al símbolo ".";- com - corresponde a la palabra "com";
(\w|$)es el tercer grupo de captura, donde\wcorresponde a cualquier;- del texto,
|es "or" operator,$indica la posición al final de la línea.
Última actualización: 26.03.2024
o